

BioBox: BioData Intelligence Platform
Build and deploy custom reasoning engines to make better data-driven decisions in drug discovery

Introduction
If you want to have a successful drug program, target selection is the most important thing you need to get right. The reality is that if you have a bad target, nothing else really matters, it is never going to work. This is why scientists spend a lot of time and resources meticulously analyzing as much data as possible to develop a compelling scientific narrative. We need to better understand the biology of the disease. The more evidence we can find, the more confident we can be in our decision-making. In this post we present our framework for accelerating scientific reasoning in drug discovery and introduce BioBox: The BioData Intelligence Platform.
BioData Intelligence Platform
We envision a platform that acts as the central repository of collective knowledge that integrates multiple data sources to weave together a cohesive data graph. Biologists can interact with and explore this graph in a simple and intuitive interface. Complex scientific logic can be modeled and tuned to assist scientists in making strong, well-reasoned, data-driven decisions.

The platform is divided into 3 layers:
Ontology - Defining what things mean in your organization
Model - Build custom graph ML models that scores things your way
Application - Put models to use in purpose built apps designed for biology
L1-Ontology: Define your data language

Speed and decisiveness is determined by the clarity of communication between different stakeholders when making a target selection decision. In practice, this boils down into getting 3 things right:
Getting everyone on your team to agree on what things mean in your organization
Improve the readability and interpretability of critical business objects
Capture how data enters and gets transformed in your research practices
Your ontology is where you create a single source of truth for your team. Every concept is unambiguously defined and their relatedness explicitly declared. As you begin building and populating your data graph, it automatically keeps track of its history to ensure proper data lineage, governance, and provenance.

L2-Model: Declare your scientific logic
Part of good scientific communication is being able to justify your rationale with data. Certain observations support our hypothesis and some may give us reason to question our assumptions. The strength of the influence depends on the type of evidence we are given. For example, you’d probably give more relevance to sequencing analyses of patient-derived tumor cells than to assays done on immortalized cells. In other words, evidence are valued with different weights. We use these considerations in our mental models that, at its fundamental level, is trying to explain the relatedness between 2 concepts.

In BioBox, we capture this logic into discrete graph models that are expertly tuned by your scientists to automatically compute a score based on all data in your graph. As new information is added to your graph, these graph models recompute to ensure your scores are always up to date. What this means for research teams is that you have a tractable and explainable way to justify scientific reasoning, that is unique to your science.
Because these graph models can be built against any two concepts in your graph, you could use them to score Gene → Phenotype, Drug → Disease, Gene → Biological Process, etc.
Graph models allows your scientists to transparently and explicitly describe data interpretation strategies and facilitates strong data-driven decision making.
L3-Application: Putting the models and graph to work
The platform makes building the data graph and the models easy, but to get real business value, computational and translational scientists must be able to interact with them. The application layer of the BioBox platform refers to the collection of ontology and graph-aware software tools that enable your scientists to interactively mine the graph for novel insights, generate data-driven reports powered by your graph models, and provides API solutions to integrate your data graph into your internal ML models.
Automatic Report Generation From Graph Models
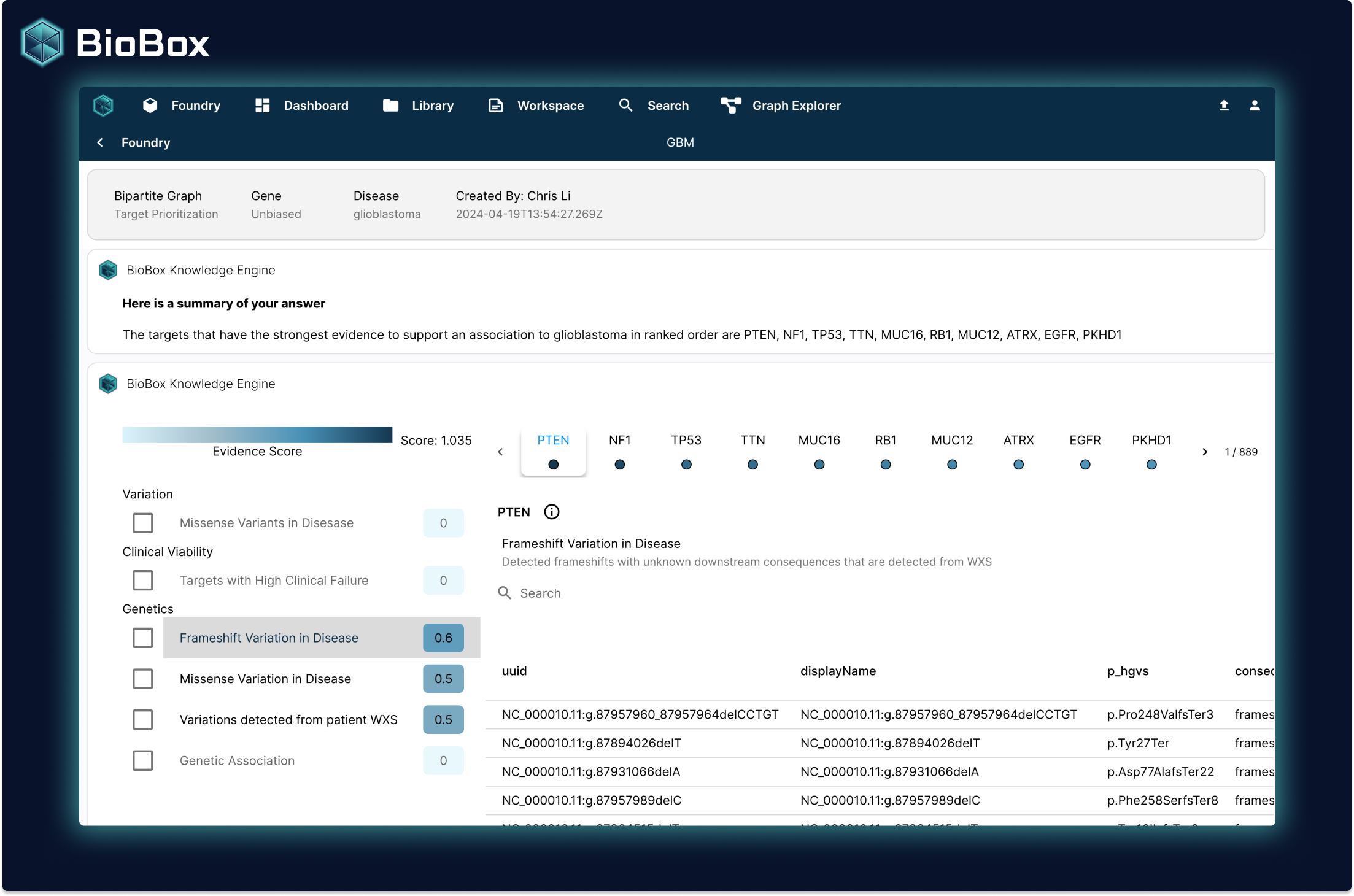
Using your graph models, scientists can rapidly generate scored target prioritization reports in seconds. These reports allows you to:
generate a scaled score of associations
get a full trace of every data point used to generate scores
one-click data snapshot and share findings with cross-functional teams
Interactive Data Graph Exploration

Put the power of your data moat in the hands of your scientists by allowing them to explore it interactively. The BioBox Graph Explorer is a ontology-aware way to navigate the rich connectivity and context of your data graph. Scientists can run graph algorithms on the fly, including community detection and path finding, to discover new insights embedded inside your proprietary and/or publicly available data. Sessions can be saved and shared with cross-functional teams to collaboratively build a scientific narrative.
Who is this for?
This platform caters to teams who
Are looking to obtain an in-depth understanding of the biology of a disease.
Need answers to complex biological questions.
Have multi-modal data (NGS, low throughput, clinical metadata, etc).
Need a flexible and customizable system that will scale with additional data and team members.
Have an internal AI strategy.
Who is this not for?
This platform is not for
Teams looking to strictly mine literature.
Teams without multi-modal data.
Teams who do not have specific biological questions they are trying to answer.
Teams looking for one size fits all knowledge graphs.
Bottom Line
The BioBox Platform is a fully integrated system for research teams to answer complex biological questions using multi-modal data. It helps you solve three things:
Clarify Communication: By establishing a shared vocabulary and a clear understanding of data relationships through the ontology layer, BioBox ensures that all team members are aligned, enhancing collaboration and efficiency in decision-making processes.
Enhance Decision-Making: Through the model layer, BioBox empowers scientists to quantify their hypotheses and test their theories with precision. This structured approach to scientific reasoning enables you to make data-driven decisions with confidence, backed by a dynamic scoring system that adapts to new data.
Drive Innovation: The application layer transforms complex data interactions into actionable insights, enabling scientists to discover novel therapeutic targets and strategies. This not only accelerates the research and development process but also opens up new avenues for innovation within drug discovery.